 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Scenario Reduction for Two-Stage Robust Optimization with Discrete Uncertainty
May 14, 2026Two-Stage Robust Optimization (2RO) with discrete uncertainty is challenging, often rendering exact solutions prohibitive. Scenario reduction alleviates this issue by selecting a small, representative subset of scenarios to enable tractable computation. However, existing methods are largely problem-agnostic, operating solely on the uncertainty set without consulting the feasible region or recourse structure. In this paper, we introduce PRISE, a problem-driven sequential lookahead heuristic that constructs reduced scenario sets by evaluating the marginal impact of each scenario. While PRISE yields high-quality scenario subsets, each selection step requires solving multiple subproblems, making it computationally expensive at scale. To address this, we propose NeurPRISE, a neural surrogate model built on a GNN-Transformer backbone that encodes the per-scenario structure via graph convolution and captures cross-scenario interactions through attention. NeurPRISE is trained via imitation learning with a gain-aware ranking objective, which distills marginal gain information from PRISE into a learned scoring function for scenario ranking and selection. Extensive results on three 2RO problems show that NeurPRISE consistently achieves competitive regret relative to comprehensive methods, maintains strong calability with varying numbers of scenarios, and delivers 7-200x speedup over PRISE. NeurPRISE also exhibits strong zero-shot generalization, effectively handling instances with larger problem scales (up to 5x), more scenarios (up to 4x), and distribution shifts.
PyVRP$^+$: LLM-Driven Metacognitive Heuristic Evolution for Hybrid Genetic Search in Vehicle Routing Problems
Apr 09, 2026Designing high-performing metaheuristics for NP-hard combinatorial optimization problems, such as the Vehicle Routing Problem (VRP), remains a significant challenge, often requiring extensive domain expertise and manual tuning. Recent advances have demonstrated the potential of large language models (LLMs) to automate this process through evolutionary search. However, existing methods are largely reactive, relying on immediate performance feedback to guide what are essentially black-box code mutations. Our work departs from this paradigm by introducing Metacognitive Evolutionary Programming (MEP), a framework that elevates the LLM to a strategic discovery agent. Instead of merely reacting to performance scores, MEP compels the LLM to engage in a structured Reason-Act-Reflect cycle, forcing it to explicitly diagnose failures, formulate design hypotheses, and implement solutions grounded in pre-supplied domain knowledge. By applying MEP to evolve core components of the state-of-the-art Hybrid Genetic Search (HGS) algorithm, we discover novel heuristics that significantly outperform the original baseline. By steering the LLM to reason strategically about the exploration-exploitation trade-off, our approach discovers more effective and efficient heuristics applicable across a wide spectrum of VRP variants. Our results show that MEP discovers heuristics that yield significant performance gains over the original HGS baseline, improving solution quality by up to 2.70\% and reducing runtime by over 45\% on challenging VRP variants.
RADAR: Learning to Route with Asymmetry-aware DistAnce Representations
Mar 05, 2026Recent neural solvers have achieved strong performance on vehicle routing problems (VRPs), yet they mainly assume symmetric Euclidean distances, restricting applicability to real-world scenarios. A core challenge is encoding the relational features in asymmetric distance matrices of VRPs. Early attempts directly encoded these matrices but often failed to produce compact embeddings and generalized poorly at scale. In this paper, we propose RADAR, a scalable neural framework that augments existing neural VRP solvers with the ability to handle asymmetric inputs. RADAR addresses asymmetry from both static and dynamic perspectives. It leverages Singular Value Decomposition (SVD) on the asymmetric distance matrix to initialize compact and generalizable embeddings that inherently encode the static asymmetry in the inbound and outbound costs of each node. To further model dynamic asymmetry in embedding interactions during encoding, it replaces the standard softmax with Sinkhorn normalization that imposes joint row and column distance awareness in attention weights. Extensive experiments on synthetic and real-world benchmarks across various VRPs show that RADAR outperforms strong baselines on both in-distribution and out-of-distribution instances, demonstrating robust generalization and superior performance in solving asymmetric VRPs.
Learning Memory-Enhanced Improvement Heuristics for Flexible Job Shop Scheduling
Mar 03, 2026The rise of smart manufacturing under Industry 4.0 introduces mass customization and dynamic production, demanding more advanced and flexible scheduling techniques. The flexible job-shop scheduling problem (FJSP) has attracted significant attention due to its complex constraints and strong alignment with real-world production scenarios. Current deep reinforcement learning (DRL)-based approaches to FJSP predominantly employ constructive methods. While effective, they often fall short of reaching (near-)optimal solutions. In contrast, improvement-based methods iteratively explore the neighborhood of initial solutions and are more effective in approaching optimality. However, the flexible machine allocation in FJSP poses significant challenges to the application of this framework, including accurate state representation, effective policy learning, and efficient search strategies. To address these challenges, this paper proposes a Memory-enhanced Improvement Search framework with heterogeneous graph representation--MIStar. It employs a novel heterogeneous disjunctive graph that explicitly models the operation sequences on machines to accurately represent scheduling solutions. Moreover, a memoryenhanced heterogeneous graph neural network (MHGNN) is designed for feature extraction, leveraging historical trajectories to enhance the decision-making capability of the policy network. Finally, a parallel greedy search strategy is adopted to explore the solution space, enabling superior solutions with fewer iterations. Extensive experiments on synthetic data and public benchmarks demonstrate that MIStar significantly outperforms both traditional handcrafted improvement heuristics and state-of-the-art DRL-based constructive methods.
Chain-of-Context Learning: Dynamic Constraint Understanding for Multi-Task VRPs
Mar 02, 2026Multi-task Vehicle Routing Problems (VRPs) aim to minimize routing costs while satisfying diverse constraints. Existing solvers typically adopt a unified reinforcement learning (RL) framework to learn generalizable patterns across tasks. However, they often overlook the constraint and node dynamics during the decision process, making the model fail to accurately react to the current context. To address this limitation, we propose Chain-of-Context Learning (CCL), a novel framework that progressively captures the evolving context to guide fine-grained node adaptation. Specifically, CCL constructs step-wise contextual information via a Relevance-Guided Context Reformulation (RGCR) module, which adaptively prioritizes salient constraints. This context then guides node updates through a Trajectory-Shared Node Re-embedding (TSNR) module, which aggregates shared node features from all trajectories' contexts and uses them to update inputs for the next step. By modeling evolving preferences of the RL agent, CCL captures step-by-step dependencies in sequential decision-making. We evaluate CCL on 48 diverse VRP variants, including 16 in-distribution and 32 out-of-distribution (with unseen constraints) tasks. Experimental results show that CCL performs favorably against the state-of-the-art baselines, achieving the best performance on all in-distribution tasks and the majority of out-of-distribution tasks.
Towards Efficient Constraint Handling in Neural Solvers for Routing Problems
Feb 17, 2026Neural solvers have achieved impressive progress in addressing simple routing problems, particularly excelling in computational efficiency. However, their advantages under complex constraints remain nascent, for which current constraint-handling schemes via feasibility masking or implicit feasibility awareness can be inefficient or inapplicable for hard constraints. In this paper, we present Construct-and-Refine (CaR), the first general and efficient constraint-handling framework for neural routing solvers based on explicit learning-based feasibility refinement. Unlike prior construction-search hybrids that target reducing optimality gaps through heavy improvements yet still struggle with hard constraints, CaR achieves efficient constraint handling by designing a joint training framework that guides the construction module to generate diverse and high-quality solutions well-suited for a lightweight improvement process, e.g., 10 steps versus 5k steps in prior work. Moreover, CaR presents the first use of construction-improvement-shared representation, enabling potential knowledge sharing across paradigms by unifying the encoder, especially in more complex constrained scenarios. We evaluate CaR on typical hard routing constraints to showcase its broader applicability. Results demonstrate that CaR achieves superior feasibility, solution quality, and efficiency compared to both classical and neural state-of-the-art solvers.
READY: Reward Discovery for Meta-Black-Box Optimization
Jan 29, 2026Meta-Black-Box Optimization (MetaBBO) is an emerging avenue within Optimization community, where algorithm design policy could be meta-learned by reinforcement learning to enhance optimization performance. So far, the reward functions in existing MetaBBO works are designed by human experts, introducing certain design bias and risks of reward hacking. In this paper, we use Large Language Model~(LLM) as an automated reward discovery tool for MetaBBO. Specifically, we consider both effectiveness and efficiency sides. On effectiveness side, we borrow the idea of evolution of heuristics, introducing tailored evolution paradigm in the iterative LLM-based program search process, which ensures continuous improvement. On efficiency side, we additionally introduce multi-task evolution architecture to support parallel reward discovery for diverse MetaBBO approaches. Such parallel process also benefits from knowledge sharing across tasks to accelerate convergence. Empirical results demonstrate that the reward functions discovered by our approach could be helpful for boosting existing MetaBBO works, underscoring the importance of reward design in MetaBBO. We provide READY's project at https://anonymous.4open.science/r/ICML_READY-747F.
DRAGON: LLM-Driven Decomposition and Reconstruction Agents for Large-Scale Combinatorial Optimization
Jan 10, 2026Large Language Models (LLMs) have recently shown promise in addressing combinatorial optimization problems (COPs) through prompt-based strategies. However, their scalability and generalization remain limited, and their effectiveness diminishes as problem size increases, particularly in routing problems involving more than 30 nodes. We propose DRAGON, which stands for Decomposition and Reconstruction Agents Guided OptimizatioN, a novel framework that combines the strengths of metaheuristic design and LLM reasoning. Starting from an initial global solution, DRAGON autonomously identifies regions with high optimization potential and strategically decompose large-scale COPs into manageable subproblems. Each subproblem is then reformulated as a concise, localized optimization task and solved through targeted LLM prompting guided by accumulated experiences. Finally, the locally optimized solutions are systematically reintegrated into the original global context to yield a significantly improved overall outcome. By continuously interacting with the optimization environment and leveraging an adaptive experience memory, the agents iteratively learn from feedback, effectively coupling symbolic reasoning with heuristic search. Empirical results show that, unlike existing LLM-based solvers limited to small-scale instances, DRAGON consistently produces feasible solutions on TSPLIB, CVRPLIB, and Weibull-5k bin packing benchmarks, and achieves near-optimal results (0.16% gap) on knapsack problems with over 3M variables. This work shows the potential of feedback-driven language agents as a new paradigm for generalizable and interpretable large-scale optimization.
Bridging Synthetic and Real Routing Problems via LLM-Guided Instance Generation and Progressive Adaptation
Nov 13, 2025Recent advances in Neural Combinatorial Optimization (NCO) methods have significantly improved the capability of neural solvers to handle synthetic routing instances. Nonetheless, existing neural solvers typically struggle to generalize effectively from synthetic, uniformly-distributed training data to real-world VRP scenarios, including widely recognized benchmark instances from TSPLib and CVRPLib. To bridge this generalization gap, we present Evolutionary Realistic Instance Synthesis (EvoReal), which leverages an evolutionary module guided by large language models (LLMs) to generate synthetic instances characterized by diverse and realistic structural patterns. Specifically, the evolutionary module produces synthetic instances whose structural attributes statistically mimics those observed in authentic real-world instances. Subsequently, pre-trained NCO models are progressively refined, firstly aligning them with these structurally enriched synthetic distributions and then further adapting them through direct fine-tuning on actual benchmark instances. Extensive experimental evaluations demonstrate that EvoReal markedly improves the generalization capabilities of state-of-the-art neural solvers, yielding a notable reduced performance gap compared to the optimal solutions on the TSPLib (1.05%) and CVRPLib (2.71%) benchmarks across a broad spectrum of problem scales.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025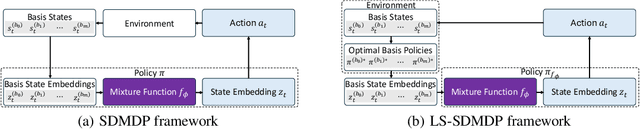
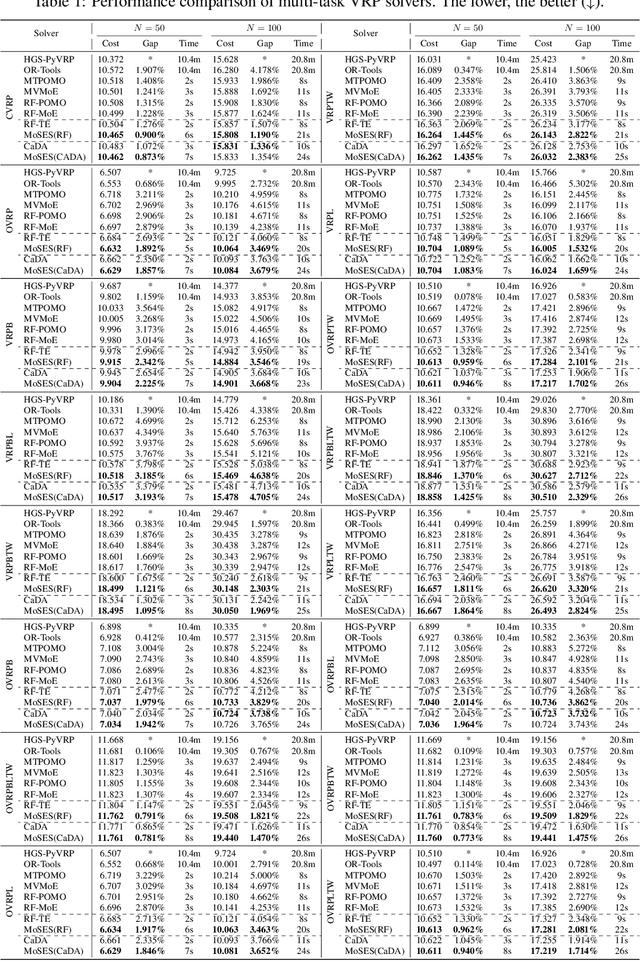
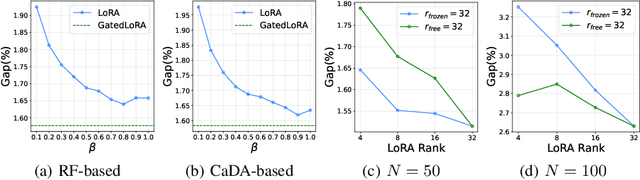
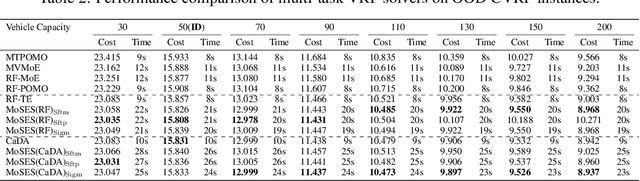
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.